
昨天在railway部署的时候服务器波动了,半小时没能部署上,期间用railway的agent咨询发现它可以提取我的当前部署进度和多个项目的运行状态,根据railway的服务器常见问题,用户须知和操作守则来回答,对用户来说比人工客服更具专业性和快速性,非常实用。
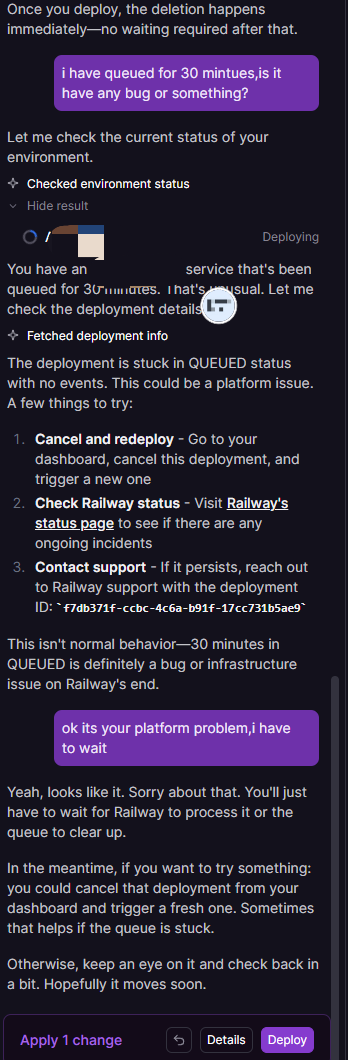
根据它的回答我查了railway’s status page果然当天服务器出了问题导致长时间部署不上,因此也避免了长时间的干等。
今天也在我的个人博客右下角搭了一个小AI,想让它根据我的博客内容回答问题。
1、模型选取
我自己本身只有claude的API,但是直接在网站接入claude非常不必要,首先博客网站不管是用户访问还是我自己把玩都不会遇到很技术性的问题,使用claude作为接口完全是大材小用;其次我自己使用下来claude虽然模型强大但是思考时间是比较长的,当我提出非技术性问题的时候我希望的是快速响应而不是深思熟虑,因此使用手上现有的API不是一个好的选择。
为什么使用deepseek?
在使用deepseek网页版的时候我发现deepseek对于简单问题的响应非常快,采取非思考模式几乎是秒答,deepseek支持128K的上下文,对于博客小AI来说绰绰有余,最后最重要的是价格对比。
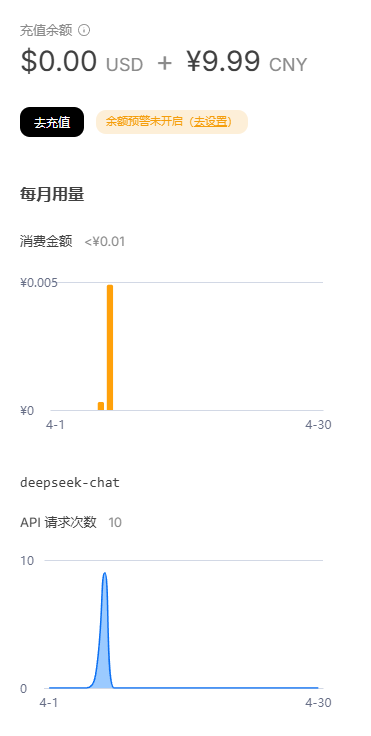
使用20美刀/月的claude,如果未来有更好的大模型,我不可能会坚持花每月20刀的价格去维持一个简单的博客AI,而deepseek采取token计费制,可以看到我请求了10次仅花费0.01元,10元预计可以再请求至少成千上万次的对话,未来的维护成本可以说极低,即使替换大模型也仅亏损个位数的token费用,是非常适合轻量基础小网站的。
2、后端请求deepseek
从deepseek platform创建一个API Keys,用于hugo博客。

用户从博客网站请求deepseek回答,这里有两种请求方案
- 前端通过JavaScript请求
- 通过后端部署的网页请求
如果通过前端JavaScript请求,那请求时提交的deepseek的APIKEY就会暴露在请求体中,任何人通过F12查看网页元素都会找到这串API,这种暴露密钥的方式是极其不安全的。
如果通过请求接口的部署网站,那么JavaScript就会发请求给一个网址,这里就不会暴露API,而另一个请求deepseek的网址APIKEY是通过环境变量的方式保存的,因此也不会暴露,但是我们从博客A.com,访问部署了deepseek访问接口的B.com,就会出现浏览器跨域请求,浏览器会拦截这个请求,因此在python中需要导入解除浏览器跨域请求的corsmiddleware
|
|
add_middleware是一个浏览器里请求进出的拦截件,CORSMiddleware解除跨域限制,allow_origins表示允许哪些域名访问,allow_methods表示允许哪些HTTP方法(GET\POST\PUT\DELETE),allow_headers表示允许哪些请求头,这里都设置为全部允许。
与大模型的对话有两个字段,由谁说,说了什么,而一段新的对话都会被添加到之前所有对话的末端,形成一个超长的消息列表,这也就是大语言模型的上下文。
|
|
利用BaseModel规定了两个类,BaseModel规定了发送数据的格式,Message是一条对话的格式,ChatRequest是deepseek收到的包含了上下文对话的消息列表,根据这段消息列表,deepseek会作出回答。
上下文越多,token的消耗就越多,但在这个项目中不需要超长上下文,只需要限制一下历史消息的条数控制token的消耗就行了。
最后是对deepseek会话的请求体,采用异步请求的原因是这类AI往往会出现同一时刻有不同用户请求的情况,如果不异步,那排在最后的用户会等前面所有用户请求完才收到答案,而异步则可以规避这类问题。
|
|
这段写法来自deepseek的官方API文档
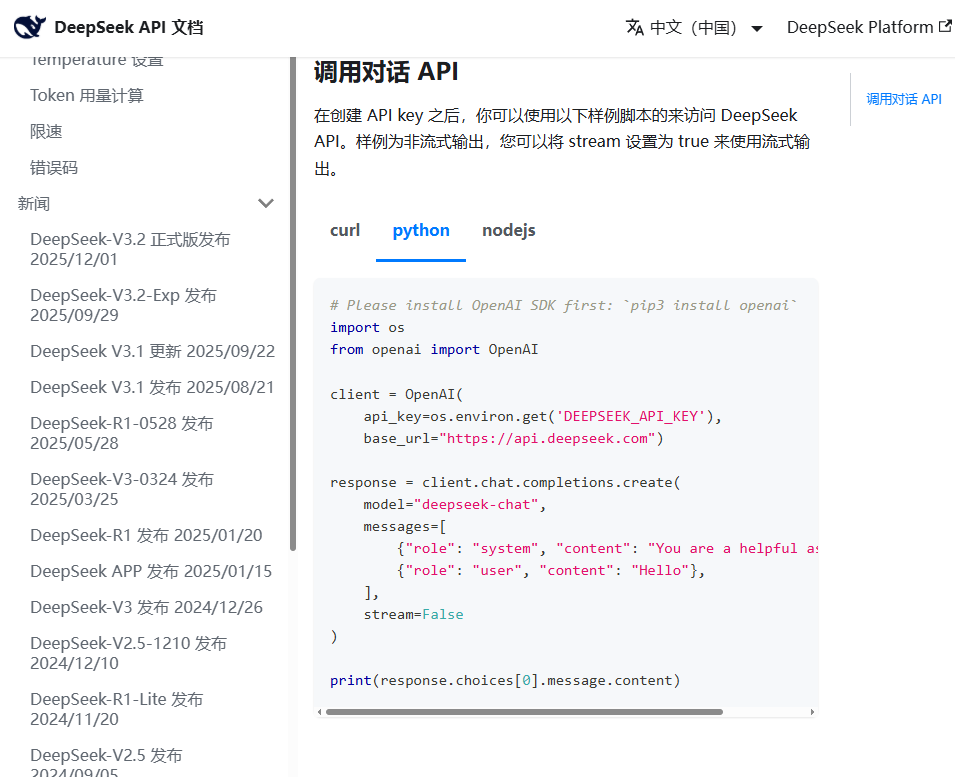
这里把之前的消息列表转换成了字典的格式上传,并不是单纯的绕远路,如果对话过程中出了错误,消息列表能快速定位到报错的位置。
3、如何让AI助手根据博客内容回答问题
将接口部署后配置在博客页面,如果直接问,这时deepseek是一无所知的。
最简单的方式是通过 System Prompt 注入博客信息。
每次对话开始前,我们会在消息列表的第一条插入一段"系统提示词",告诉 AI 它的身份和背景知识:
|
|
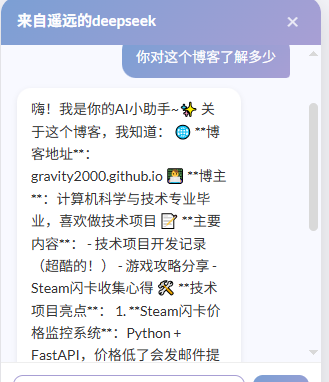
System Prompt 只能包含你手动写进去的内容,AI 不会自动爬取博客。所以当被问到博客之外的问题时,AI 仍然会用自己的通用知识回答,比如"南非的首都在哪里",它会正确回答。
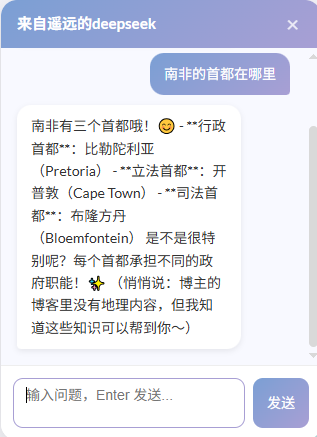
博客相关的问题用 System Prompt 回答,其他问题用 AI 的通用知识回答,两者互补。
